Pernahkah Anda berpikir untuk membangun chatbot yang dapat menjawab pertanyaan berdasarkan dokumen perusahaan? Bukan chatbot yang memberikan jawaban sembarangan atau mengalami hallucination, tetapi chatbot yang benar-benar mengambil informasi dari dokumen asli?
Dalam tutorial ini, kita akan membangun sistem RAG (Retrieval-Augmented Generation) Chatbot menggunakan Telkom LLM dan Telkom Embedding API tersedia di Apilogy yang diorkestrasi dengan n8n.
Akses template workflow lengkap di akhir artikel ini.
Apa itu RAG dan Mengapa Penting?
RAG adalah pendekatan yang menggabungkan sistem pencarian (retrieval) dengan generasi teks. Bayangkan seperti ini: LLM tradisional seperti seseorang yang telah membaca banyak buku, namun memiliki keterbatasan:
- Pengetahuannya terbatas hingga tanggal tertentu (knowledge cutoff)
- Kadang memberikan jawaban yang tidak akurat ketika tidak mengetahui jawabannya (hallucination)
- Tidak memiliki akses ke dokumen internal perusahaan Anda
RAG mengatasi masalah ini dengan alur kerja sebagai berikut:
User bertanya → Cari dokumen yang relevan → Berikan dokumen tersebut ke LLM → LLM menjawab berdasarkan dokumen
Hasilnya adalah jawaban yang selalu faktual dan berdasarkan dokumen Anda sendiri.
Yang Anda Butuhkan
Tools and Services
| Item | Deskripsi | Biaya |
|---|---|---|
| n8n | Platform workflow automation untuk orkestrasi | Gratis (self-hosted) |
| Telkom Embedding API | Mengubah teks menjadi vektor dimensi | Per request (ada opsi free plan) |
| Telkom LLM API | Model bahasa AI untuk menghasilkan jawaban | Per request (ada opsi free plan) |
| Supabase | Database PostgreSQL dengan pgvector | Gratis (500MB) |
Prerequisites
- n8n versi 2.4.6 atau lebih baru telah terinstall
- API key Telkom Embedding dan LLM (registrasi di platform APILOGY)
- Akun Supabase (gratis)
- Pemahaman dasar JavaScript
Arsitektur Sistem
Sebelum memulai implementasi, penting untuk memahami bagaimana sistem akan bekerja. Sistem RAG kita terdiri dari dua workflow utama:
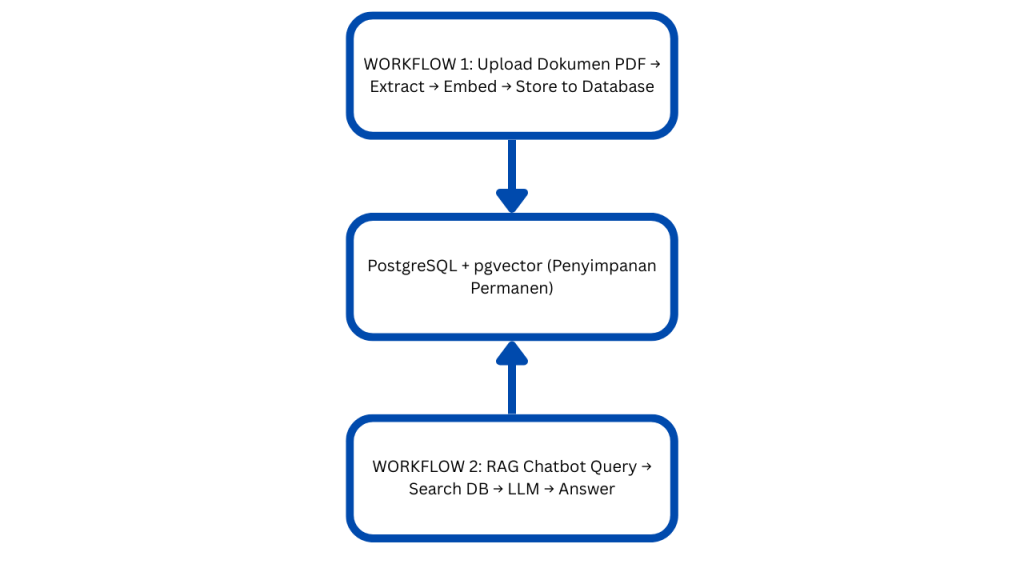
Workflow 1: Knowledge Processing
Dijalankan satu kali untuk setiap dokumen baru. Bertanggung jawab untuk memproses dokumen dan menyimpannya sebagai vector embeddings.
Workflow 2: RAG Chatbot
Dijalankan setiap kali user mengirimkan pertanyaan. Bertanggung jawab untuk mencari informasi relevan dan menghasilkan jawaban.
Part 1: Setup Database
Langkah pertama adalah menyiapkan database untuk menyimpan vector embeddings.
Step 1: Membuat Project di Supabase
- Kunjungi https://supabase.com
- Sign up atau login dengan akun GitHub
- Isi form new organization
- Klik tombol “Start Your Project”
- Klik tombol “New Project”
- Isi form dengan detail berikut:
- Project Name: telkom-rag-chatbot (bebas)
- Database Password: buat password yang kuat dan simpan dengan aman
- Region: Asia Pacific untuk latensi optimal
- Klik “Create new project”
Step 2: Setup Database Schema
Setelah project siap, kita perlu membuat table untuk menyimpan vector embeddings.
- Di Supabase dashboard, navigasi ke “SQL Editor” di sidebar kiri
- Klik “New query”
- Copy dan paste SQL script berikut:
-- Aktifkan extension pgvectorCREATE EXTENSION IF NOT EXISTS vector;-- Buat table untuk menyimpan embeddingsCREATE TABLE vector_store ( id TEXT PRIMARY KEY, embedding vector(768), -- 768 adalah dimensi dari Telkom Embedding API metadata JSONB NOT NULL, -- Informasi tambahan (text, document name, dll) created_at TIMESTAMP DEFAULT NOW());-- Buat index untuk fast similarity search menggunakan IVFFlatCREATE INDEX vector_store_embedding_idx ON vector_store USING ivfflat (embedding vector_cosine_ops)WITH (lists = 100);-- Buat index untuk metadata searchCREATE INDEX vector_store_metadata_idx ON vector_store USING gin(metadata);
Klik tombol “Run” atau tekan Ctrl+Enter. Pastikan muncul pesan: “Success. No rows returned”
Penjelasan Schema:
- id: Unique identifier untuk setiap chunk dokumen
- embedding: Vector dengan 768 dimensi dari Telkom Embedding API
- metadata: JSONB field yang menyimpan informasi seperti teks asli, nama dokumen, index chunk, dll
- created_at: Timestamp untuk tracking kapan data di-insert
- IVFFlat index: Digunakan untuk mempercepat similarity search menggunakan cosine distance
Step 3: Mendapatkan Connection String
- Di dashboard Supabase, navigasi ke “Settings” → “Database”
- Scroll ke bagian “Connection string”
- Pilih tab “URI”
- Copy connection string yang formatnya seperti ini:
postgresql://postgres:[YOUR-PASSWORD]@db.xxx.supabase.co:5432/postgres
- Simpan connection string ini, akan digunakan untuk konfigurasi n8n
Database Anda sekarang sudah siap untuk digunakan.
PART 2: Workflow 1 – Upload dan Process Dokumen

Workflow pertama bertugas untuk mengonversi dokumen PDF menjadi vector embeddings dan menyimpannya ke database.
Alur kerja:
PDF Upload → Extract Text → Chunk → Batch → Embed (Telkom API) → Format → Insert to PostgreSQL
Step 1: Membuat Workflow Baru di n8n
- Buka aplikasi n8n Anda
- Klik “New workflow”
- Rename workflow menjadi: “Telkom RAG – Document Upload”
- Simpan workflow
Step 2: Menambahkan Form Trigger Node

Node pertama adalah entry point untuk menerima file upload dari user.
Node Type: Form Trigger

- Cari node “Form Trigger” di panel node
- Drag node ke canvas
- Konfigurasi sebagai berikut:
- Form Title: “Upload your documents”
- Form Description: “Upload PDF, CSV, or TXT files for processing”
- Klik “Add Field”:
- Field Label: file
- Field Type: File
- Accept File Types: .pdf, .csv, .txt
- Required: aktifkan toggle
- Save dan copy Production URL
URL ini akan digunakan untuk mengakses form upload dari browser.
Step 3: Extract Text dari File

Node Type: Extract from File
Node ini akan membaca file binary dan mengekstrak teks dari PDF.

- Tambahkan node “Extract from File”
- Hubungkan dengan Form Trigger
- Konfigurasi:
- Operation: pdf
- Binary Property Name: file (sesuai dengan nama field di form)
- Options: biarkan default
Output yang dihasilkan:
{ "text": "Full text content from PDF...", "numpages": 5, "info": {...}}
Catatan: Node ini hanya bekerja untuk PDF yang berbasis teks. Untuk PDF hasil scan (image-based), diperlukan preprocessing dengan OCR.
Step 4: Chunking Text
Node Type: Code (JavaScript)
Dokumen panjang perlu dipotong menjadi chunks kecil agar dapat diproses oleh embedding model. Node ini bertanggung jawab untuk melakukan chunking dengan overlap.
- Tambahkan node Code
- Rename menjadi: Chunk Text
- Hubungkan dari node Extract from File
- Paste code berikut:
// Ambil input dari node sebelumnyaconst input = $input.first().json;const text = input.text || '';// Ambil nama dokumen dari filenamelet documentName = 'Untitled';if ($input.first().binary?.file?.fileName) { documentName = $input.first().binary.file.fileName .replace(/\.[^/.]+$/, ''); // Hapus extension}// Validasi bahwa text berhasil di-extractif (!text || text.trim() === '') { throw new Error('No text extracted from document');}console.log(`Processing: ${documentName} (${text.length} characters)`);// Parameter chunkingconst chunkSize = 500; // 500 karakter per chunkconst overlap = 50; // 50 karakter overlap antar chunkconst chunks = [];// Split text dengan overlapfor (let i = 0; i < text.length; i += (chunkSize - overlap)) { const chunk = text.substring(i, i + chunkSize).trim(); if (chunk.length > 0) { chunks.push(chunk); }}console.log(`Created ${chunks.length} chunks`);// Return sebagai array of itemsreturn chunks.map((chunk, index) => ({ json: { text: chunk, documentName: documentName, chunkIndex: index, totalChunks: chunks.length }}));
Mengapa 500 characters dan 50 overlap?
500 characters: Ukuran ini optimal karena:
- Cukup besar untuk memiliki konteks yang meaningful (~150-250 tokens)
- Cukup kecil untuk tidak melebihi token limit embedding model
- Berdasarkan research, range 400-600 characters memberikan hasil terbaik untuk retrieval accuracy
50 characters overlap: Overlap diperlukan untuk:
- Menjaga kontinuitas informasi yang mungkin terpotong di batas chunk
- Mengikuti rule of thumb 10% dari chunk size
- Memastikan kalimat yang terpotong tetap dapat dibaca di chunk berikutnya
Bayangkan seperti memotong buku menjadi bab-bab yang overlap sedikit, sehingga pembaca tidak kehilangan konteks saat berpindah bab.
Output: Jika dokumen memiliki 5000 characters, akan menghasilkan sekitar 11 chunks (items).
Step 5: Prepare Batch untuk API
Node Type: Code (JavaScript)
Telkom Embedding API dapat menerima multiple texts sekaligus. Node ini mengumpulkan semua chunks dan mempersiapkannya dalam format batch.
- Tambahkan node Code
- Rename menjadi:
Prepare Batch - Hubungkan dari Chunk Text
- Paste code:
// Kumpulkan semua chunks dari node sebelumnyaconst items = $input.all();// Extract hanya text untuk dikirim ke APIconst textList = items.map(item => item.json.text);console.log(`Preparing ${textList.length} chunks for embedding`);// Simpan metadata lengkap untuk digunakan nanticonst originalItems = items.map(item => item.json);// Return dalam format yang dibutuhkan APIreturn [{ json: { text_list: textList, // Array of strings untuk API originalItems: originalItems // Metadata lengkap untuk rekombinasi nanti }}];
Mengapa perlu batch processing?
Tanpa batch, sistem harus melakukan 11 API calls terpisah (satu per chunk):
API call 1 → chunk 1 → tunggu responseAPI call 2 → chunk 2 → tunggu response...API call 11 → chunk 11Total waktu: 11 × 0.5 detik = 5.5 detikTotal biaya: 11 × harga per request
Dengan batch, semua chunks dikirim dalam satu request:
API call 1 → [chunk 1, 2, 3, ..., 11] sekaligusTotal waktu: 1 × 2 detik = 2 detikTotal biaya: 1 × harga per requestPenghematan: 64% waktu dan 91% biaya
Mengapa menyimpan originalItems?
API hanya membutuhkan array of strings (text_list), tetapi kita memerlukan metadata (documentName, chunkIndex, dll) untuk menyimpan ke database nanti. originalItems berfungsi sebagai “memory” yang membawa metadata dari awal hingga akhir workflow.
Analogi: Seperti mengirim paket melalui kurir. text_list adalah barangnya, originalItems adalah label alamatnya. Kita tetap membawa label agar tahu barang mana untuk siapa.
Output:
{ "text_list": ["chunk 1 text", "chunk 2 text", ..., "chunk 11 text"], "originalItems": [ {"text": "chunk 1 text", "documentName": "Doc", "chunkIndex": 0, "totalChunks": 11}, {"text": "chunk 2 text", "documentName": "Doc", "chunkIndex": 1, "totalChunks": 11}, ... ]}
Step 6: Memanggil Telkom Embedding API

Node Type: HTTP Request
Node ini mengirim chunks ke Telkom Embedding API untuk dikonversi menjadi vectors.
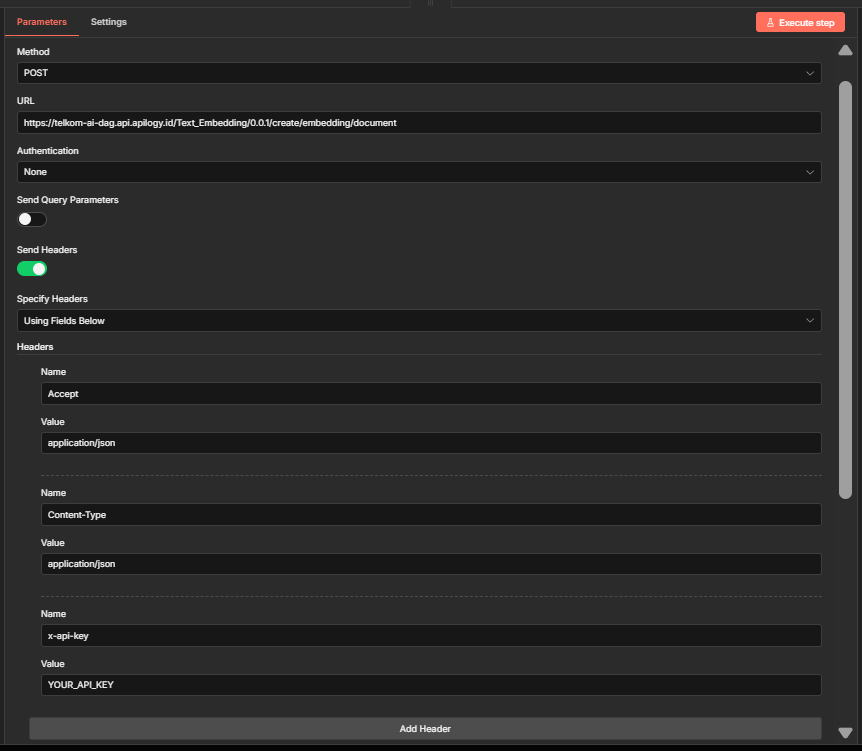

- Tambahkan node HTTP Request
- Rename menjadi:
Telkom Embedding API - Konfigurasi:
Method: POSTURL: https://telkom-ai-dag.api.apilogy.id/Text_Embedding/0.0.1/create/embedding/documentAuthentication: None (menggunakan header)Send Headers: Yes - Name: x-api-key Value: [YOUR_TELKOM_EMBEDDING_API_KEY] - Name: Content-Type Value: application/jsonSend Body: YesBody Content Type: JSONJSON Body:={{ JSON.stringify({ text_list: $json.text_list }) }}
Request yang dikirim:
json
{ "text_list": [ "APILOGY adalah API Marketplace platform...", "Platform ini menyediakan berbagai API...", ... ]}
Response yang diterima:
json
{ "embeddings": [ [0.0466, 0.0224, 0.0088, ...], // 768 numbers untuk chunk 1 [0.0123, 0.0456, 0.0789, ...], // 768 numbers untuk chunk 2 ... ]}
Apa itu embedding?
Embedding adalah representasi matematika dari teks dalam bentuk array of numbers. Teks yang memiliki makna serupa akan menghasilkan vector yang serupa pula.
Contoh:
Text: "APILOGY platform"Embedding: [0.1, 0.2, 0.3, 0.4, ...]Text: "APILOGY adalah platform"Embedding: [0.11, 0.19, 0.31, 0.41, ...] <- Sangat mirip!Text: "Harga saham hari ini"Embedding: [0.8, 0.1, 0.5, 0.2, ...] <- Sangat berbeda!
Dengan representasi vector, komputer dapat mengukur seberapa mirip dua teks secara semantik menggunakan operasi matematika.
Step 7: Format untuk PostgreSQL

Node Type: Code (JavaScript)
Node ini menggabungkan embeddings dari API dengan metadata yang disimpan sebelumnya, mempersiapkan data dalam format yang siap untuk di-insert ke database.
- Tambahkan node Code
- Rename menjadi:
Format for PostgreSQL - Paste code:
// Ambil embeddings dari response APIconst currentItem = $input.first().json;const embeddings = currentItem.embeddings || [];// Ambil metadata dari node "Prepare Batch"const prepareBatchData = $('Prepare Batch').first().json;const originalItems = prepareBatchData.originalItems || [];// Validasiif (!Array.isArray(embeddings) || embeddings.length === 0) { throw new Error('No embeddings received from API');}console.log(`Received ${embeddings.length} embeddings`);console.log(`Embedding dimension: ${embeddings[0].length}`);// Gabungkan embedding dengan metadataconst documents = embeddings.map((embedding, index) => { const meta = originalItems[index] || {}; const docName = (meta.documentName || 'untitled').toString(); // Buat ID yang safe untuk database const safeDocName = docName.replace(/[^a-zA-Z0-9]/g, '_'); const id = `${safeDocName}_chunk_${meta.chunkIndex}_${Date.now()}_${index}`; return { json: { id: id, embedding: JSON.stringify(embedding), // Convert array ke string metadata: JSON.stringify({ // Convert object ke string text: meta.text || '', documentName: docName, chunkIndex: meta.chunkIndex || 0, totalChunks: meta.totalChunks || 1, uploadedAt: new Date().toISOString() }) } };});console.log(`Formatted ${documents.length} documents for storage`);return documents;
Proses yang terjadi:
Input (1 item dari API):
json
{ "embeddings": [[0.1, 0.2, ...], [0.3, 0.4, ...], ...], "originalItems": [{...metadata...}, {...}, ...]}
Output (11 items siap untuk database):
json
[ { "id": "MyDoc_chunk_0_1737910800_0", "embedding": "[0.1,0.2,...]", "metadata": "{\"text\":\"...\",\"documentName\":\"MyDoc\",...}" }, {...}, ...]
Step 8: Insert ke PostgreSQL
Node Type: Postgres
Node terakhir dalam workflow upload, bertanggung jawab untuk menyimpan data ke database.
- Tambahkan node Postgres (Execute a SQL query)
- Hubungkan dari Format for PostgreSQL
- Konfigurasi:
- Credential: Buat credential baru dengan connection string dari Supabase
- Operation:
Execute Query - Query:
sql
INSERT INTO vector_store (id, embedding, metadata, created_at)VALUES ( '{{ $json.id }}', '{{ $json.embedding }}'::vector, '{{ $json.metadata }}'::jsonb, NOW())ON CONFLICT (id) DO UPDATE SET embedding = EXCLUDED.embedding, metadata = EXCLUDED.metadata, created_at = NOW();
Penjelasan SQL:
'{{ $json.id }}': Dynamic value dari node sebelumnya, diambil oleh n8n template syntax::vector: Type casting string menjadi vector type PostgreSQL::jsonb: Type casting string menjadi JSONB typeON CONFLICT ... DO UPDATE: Upsert operation (insert jika belum ada, update jika sudah ada)
Execution:
Node ini akan execute sebanyak 11 kali (sekali per chunk), masing-masing insert satu row ke database. Total durasi sekitar 5 detik untuk 11 chunks.
Step 9: Testing Workflow Upload
- Klik tombol “Execute Workflow” di n8n
- Buka Production URL yang di-copy dari Form Trigger
- Upload file PDF test (misalnya dokumen 5 halaman)
- Tunggu proses selesai (sekitar 15-20 detik)
- Verifikasi di Supabase SQL Editor:
sql
-- Cek jumlah chunks yang tersimpanSELECT COUNT(*) FROM vector_store;-- Harusnya return: 11 (atau jumlah chunks sesuai dokumen)-- Lihat sample dataSELECT metadata->>'documentName' as doc_name, metadata->>'chunkIndex' as chunk_index, LEFT(metadata->>'text', 50) as text_previewFROM vector_storeORDER BY created_at DESCLIMIT 5;

Jika query mengembalikan data, berarti workflow upload berhasil. Database Anda sekarang berisi vector embeddings dari dokumen.
PART 3: Workflow 2 – RAG Chatbot

Workflow kedua bertugas untuk menerima pertanyaan dari user, mencari chunks yang relevan, dan menghasilkan jawaban menggunakan LLM.
Alur kerja:
Webhook → Extract Message → Embed Query → Get All Vectors → Search & Calculate Similarity → Build Context → Create Prompt → LLM → Format Response → Return to User
Step 1: Membuat Workflow Baru
- Buat workflow baru di n8n
- Rename menjadi: “Telkom RAG – Chatbot“
Step 2: Menambahkan Webhook Trigger

Node Type: Webhook

Entry point untuk menerima pertanyaan via HTTP POST request.
- Tambahkan node Webhook
- Konfigurasi:
- HTTP Method:
POST - Path:
telkom-rag-chatbot - Respond: pilih
Using 'Respond to Webhook' Node
- HTTP Method:
- Simpan dan copy Production URL
Testing webhook:
bash
curl -X POST 'YOUR-WEBHOOK-URL' \ -H 'Content-Type: application/json' \ -d '{"message": "Apa itu APILOGY?"}'
Step 3: Extract dan Validasi Message

Node Type: Code
Node sederhana untuk extract dan validasi pesan dari user.
- Tambahkan node Code
- Rename menjadi:
Extract Message - Paste code:
javascript
const body = $input.first().json.body || $input.first().json;const userMessage = (body.message || body.query || '').trim();// Validasi bahwa message adaif (!userMessage) { throw new Error('Message required. Send JSON: {"message": "your question"}');}console.log(`[RAG] User question: ${userMessage}`);return [{ json: { userMessage } }];
Step 4: Embed User Query

Node Type: HTTP Request
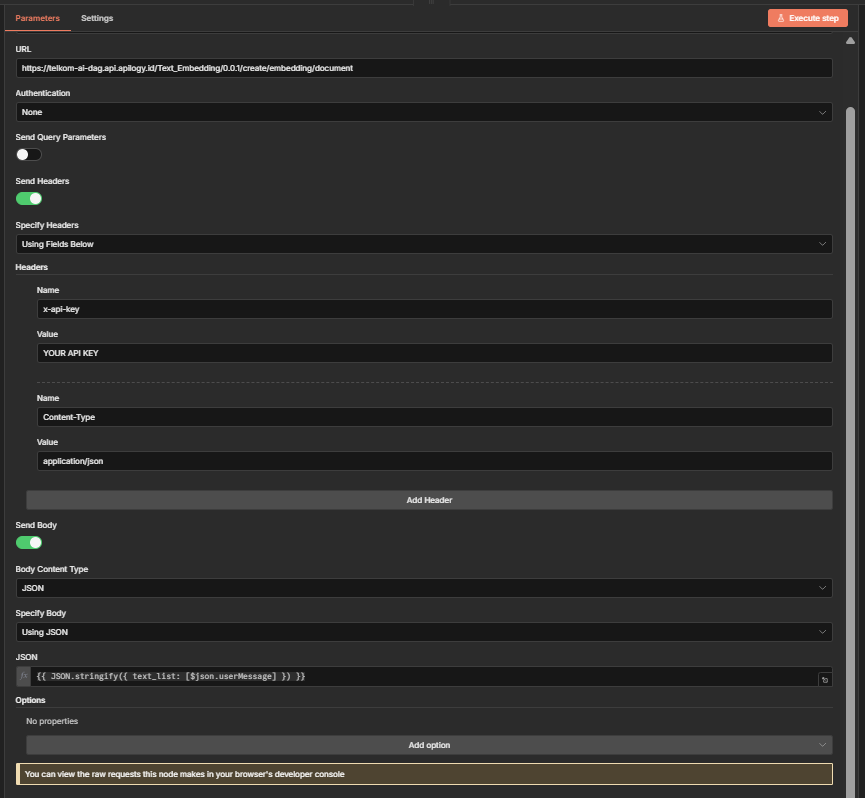
Pertanyaan user perlu dikonversi menjadi vector agar dapat dibandingkan dengan dokumen di database.
- Tambahkan node HTTP Request
- Rename menjadi:
Embed Query - Konfigurasi sama seperti Telkom Embedding API di workflow 1, tetapi dengan JSON Body:
javascript
={{ JSON.stringify({ text_list: [$json.userMessage] }) }}
Perhatikan bahwa hanya ada satu text (pertanyaan user), bukan array of texts.
Response:
json
{ "embeddings": [ [0.052, 0.017, 0.034, ...] // 768 numbers untuk pertanyaan user ]}
Step 5: Ambil Semua Vectors dari Database

Node Type: Postgres
Query sederhana untuk mengambil semua data dari database.
- Tambahkan node Postgres
- Pilih credential Supabase yang sama
- Operation:
Execute Query - Query:
sql
SELECT id, embedding::text as embedding_text, metadata::text as metadata_text FROM vector_store;
Catatan: Untuk database dengan kurang dari 10,000 chunks, pendekatan ini masih cukup cepat. Kita akan menghitung similarity di JavaScript untuk reliabilitas yang lebih baik di n8n. Untuk database yang lebih besar, dapat dioptimasi dengan native pgvector query.
Output: Array of objects, masing-masing berisi id, embedding (sebagai text), dan metadata (sebagai text).
Step 6: Search dan Build Context

Node Type: Code (JavaScript)
Ini adalah node paling krusial dalam RAG system. Node ini bertanggung jawab untuk:
- Menghitung similarity antara query dan semua dokumen
- Mengurutkan berdasarkan similarity
- Mengambil top 3 yang paling relevan
- Membangun context untuk LLM
- Tambahkan node Code
- Rename menjadi:
Search & Build Context - Paste code lengkap:
javascript
// Ambil query embedding dan data dari nodes sebelumnyaconst queryEmbedding = $('Embed Query').first().json.embeddings[0];const userMessage = $('Extract Message').first().json.userMessage;const allDocs = $input.all();// Validasiif (!queryEmbedding || allDocs.length === 0) { return [{ json: { context: 'Tidak ada dokumen tersedia dalam database.', userMessage, hasContext: false } }];}console.log(`[RAG] Searching through ${allDocs.length} documents...`);// Fungsi untuk menghitung cosine similarityfunction cosineSimilarity(vectorA, vectorB) { if (!vectorA || !vectorB || vectorA.length !== vectorB.length) { return 0; } let dotProduct = 0; let normA = 0; let normB = 0; for (let i = 0; i < vectorA.length; i++) { dotProduct += vectorA[i] * vectorB[i]; normA += vectorA[i] * vectorA[i]; normB += vectorB[i] * vectorB[i]; } return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));}// Hitung similarity untuk setiap dokumenconst results = [];for (const doc of allDocs) { try { // Parse embedding dan metadata dari string const embedding = JSON.parse(doc.json.embedding_text); const metadata = JSON.parse(doc.json.metadata_text); // Hitung similarity const similarity = cosineSimilarity(queryEmbedding, embedding); results.push({ id: doc.json.id, text: metadata.text || '', documentName: metadata.documentName || 'Unknown', chunkIndex: metadata.chunkIndex || 0, similarity: similarity }); } catch (err) { console.error(`Error processing document ${doc.json.id}:`, err.message); }}if (results.length === 0) { return [{ json: { context: 'Gagal memproses dokumen.', userMessage, hasContext: false } }];}// Sort berdasarkan similarity (tertinggi ke terendah)results.sort((a, b) => b.similarity - a.similarity);// Ambil top 3 resultsconst topResults = results.slice(0, 3);console.log(`[RAG] Top similarity: ${(topResults[0].similarity * 100).toFixed(1)}%`);// Check apakah relevan (minimum 20% similarity)if (topResults[0].similarity < 0.2) { return [{ json: { context: 'Tidak ada informasi yang relevan ditemukan dalam dokumen.', userMessage, hasContext: false } }];}// Build context dari top 3 chunksconst contextParts = topResults.map((result, index) => { const similarityPercent = Math.round(result.similarity * 100); return `[Dokumen ${index + 1}: ${result.documentName} (Chunk #${result.chunkIndex}), Relevansi: ${similarityPercent}%]${result.text}`;});const context = contextParts.join('\n\n---\n\n');return [{ json: { context: context, userMessage: userMessage, hasContext: true, documentsUsed: topResults.length, topSimilarity: Math.round(topResults[0].similarity * 100) }}];
Apa itu Cosine Similarity?
Cosine similarity adalah metode matematika untuk mengukur seberapa mirip dua vector. Nilai berkisar dari -1 (sangat berbeda) hingga 1 (identik).
Formula: similarity = (A · B) / (||A|| × ||B||)
Interpretasi:
- 1.0 = Identik (100% sama)
- 0.8-0.9 = Sangat mirip (sangat relevan)
- 0.5-0.7 = Cukup mirip (cukup relevan)
- 0.2-0.4 = Agak mirip (kurang relevan)
- < 0.2 = Tidak mirip (tidak relevan)
Contoh dalam konteks RAG:
Query: "Apa itu APILOGY?"Chunk 1: "APILOGY adalah API Marketplace platform..."Similarity: 0.87 (87%) - Sangat relevanChunk 2: "Platform ini menyediakan berbagai API..."Similarity: 0.78 (78%) - RelevanChunk 3: "Harga saham Telkom hari ini..."Similarity: 0.23 (23%) - Tidak relevan (di-filter)
Output:
json
{ "context": "[Dokumen 1: Terms (Chunk #5), Relevansi: 87%]\nAPILOGY adalah API Marketplace platform...\n\n---\n\n[Dokumen 2: Terms (Chunk #6), Relevansi: 78%]\nPlatform ini menyediakan...", "userMessage": "Apa itu APILOGY?", "hasContext": true, "documentsUsed": 3, "topSimilarity": 87}
Step 7: Create RAG Prompt

Node Type: Code
Node ini membangun prompt yang akan dikirim ke LLM, termasuk instruksi dan context dari dokumen.
- Tambahkan node Code
- Rename menjadi:
Create Prompt - Paste code:
javascript
const data = $input.first().json;// Jika tidak ada context yang relevanif (!data.hasContext) { return [{ json: { prompt: `Pengguna bertanya: "${data.userMessage}"Maaf, informasi tidak tersedia dalam dokumen yang ada. Sampaikan kepada pengguna dengan sopan bahwa informasi yang diminta tidak ditemukan dalam database saat ini.`, hasContext: false } }];}// Build prompt lengkap dengan instruksi dan contextconst ragPrompt = `Anda adalah AI assistant yang membantu menjawab pertanyaan berdasarkan dokumen yang tersedia.=== INSTRUKSI PENTING ===1. Jawab pertanyaan HANYA berdasarkan KONTEKS yang diberikan di bawah ini2. Jika informasi dalam KONTEKS cukup untuk menjawab, berikan jawaban yang jelas dan lengkap dalam Bahasa Indonesia3. Jika informasi dalam KONTEKS tidak cukup untuk menjawab pertanyaan, katakan dengan jujur bahwa informasi tersebut tidak tersedia4. JANGAN membuat atau mengarang informasi yang tidak ada dalam KONTEKS5. Jika relevan, sebutkan sumber dokumen dalam jawaban (contoh: "Berdasarkan dokumen Terms & Conditions...")6. Gunakan bahasa yang natural dan mudah dipahami=== KONTEKS DARI DOKUMEN ===${data.context}=== AKHIR KONTEKS ====== PERTANYAAN PENGGUNA ===${data.userMessage}=== INSTRUKSI JAWABAN ===Berikan jawaban yang informatif dan bermanfaat berdasarkan konteks di atas. Jika informasi tidak cukup, katakan dengan jujur.Jawaban:`;return [{ json: { prompt: ragPrompt, hasContext: true, metadata: { documentsUsed: data.documentsUsed, topSimilarity: data.topSimilarity } }}];
Mengapa prompt engineering penting?
LLM membutuhkan instruksi yang jelas agar dapat memberikan output yang sesuai harapan. Tanpa instruksi yang eksplisit:
- LLM mungkin menjawab berdasarkan knowledge internal daripada context yang diberikan
- LLM mungkin membuat informasi (hallucination) ketika tidak mengetahui jawabannya
- Format jawaban mungkin tidak konsisten
Dengan instruksi yang jelas dan terstruktur:
- LLM fokus pada context yang diberikan
- LLM lebih jujur ketika informasi tidak cukup
- Kualitas jawaban lebih konsisten dan reliable
Analogi: Seperti memberikan briefing kepada karyawan baru sebelum meeting dengan klien. Tanpa briefing yang jelas, karyawan mungkin memberikan informasi yang tidak akurat atau tidak relevan.
Step 8: Memanggil Telkom LLM API

Node Type: HTTP Request

Node ini mengirim prompt yang telah dipersiapkan ke Telkom LLM untuk menghasilkan jawaban.
- Tambahkan node HTTP Request
- Rename menjadi:
Telkom LLM - Konfigurasi:
Method: POSTURL: https://telkom-ai-dag.api.apilogy.id/Telkom-LLM/0.0.4/llm/chat/completionsSend Headers: Yes - Name: x-api-key Value: [YOUR_TELKOM_LLM_API_KEY] - Name: Content-Type Value: application/jsonSend Body: YesBody Content Type: JSONJSON Body:={{ JSON.stringify({ model: 'telkom-ai', messages: [ { role: 'user', content: $json.prompt } ], max_tokens: 1000, temperature: 0.7, stream: false}) }}
Parameter explained:
- max_tokens: 1000 (maksimum panjang respons, sekitar 750 kata)
- temperature: 0.7 (balance antara factual dan creative. 0 = sangat faktual, 1 = sangat kreatif)
- stream: false (menerima complete response sekaligus, bukan streaming)
Response yang diterima:
json
{ "choices": [ { "message": { "content": "APILOGY adalah API Marketplace platform yang dikelola oleh PT Telekomunikasi Indonesia Tbk (Telkom). Platform ini menyediakan berbagai API untuk developer, memungkinkan mereka untuk mengakses layanan Telkom dengan mudah." } } ]}
Step 9: Format Response

Node Type: Code
Memformat response final sebelum dikirim ke user, termasuk menambahkan metadata.
- Tambahkan node Code
- Rename menjadi:
Format Response - Paste code:
javascript
const llmResponse = $input.first().json;const promptInfo = $('Create Prompt').first().json;const userMessage = $('Extract Message').first().json.userMessage;// Extract jawaban dari LLM responseconst answer = llmResponse.choices[0].message.content;// Return formatted response dengan metadatareturn [{ json: { answer: answer, userMessage: userMessage, metadata: { hasContext: promptInfo.hasContext, documentsUsed: promptInfo.metadata?.documentsUsed || 0, topSimilarity: promptInfo.metadata?.topSimilarity || 0, model: 'telkom-ai', timestamp: new Date().toISOString() } }}];
Mengapa metadata penting?
Metadata memberikan informasi tambahan yang berguna untuk:
- Tracking: Berapa dokumen yang digunakan untuk menjawab?
- Quality assurance: Seberapa relevan dokumen yang ditemukan (similarity score)?
- Debugging: Jika jawaban tidak akurat, dapat ditelusuri dari metadata
- Analytics: Dapat digunakan untuk menganalisis performa sistem
Step 10: Respond to Webhook

Node Type: Respond to Webhook
Node terakhir yang mengirimkan response kembali ke user yang melakukan request.
- Tambahkan node Respond to Webhook
- Hubungkan dari Format Response
- Konfigurasi:
- Respond With:
All Incoming Items - Response Body: biarkan default (akan otomatis mengirim JSON)
- Respond With:
Workflow sekarang lengkap dan siap untuk ditest.
Step 11: Testing RAG Chatbot
- Pastikan workflow dalam status active
- Test dengan curl command:
bash
curl -X POST 'YOUR-CHATBOT-WEBHOOK-URL' \ -H 'Content-Type: application/json' \ -d '{ "message": "Apa itu APILOGY?" }'
Expected response:
json
{ "answer": "APILOGY adalah API Marketplace platform yang dikelola oleh PT Telekomunikasi Indonesia Tbk (Telkom). Platform ini menyediakan berbagai API untuk developer, memungkinkan mereka untuk mengakses layanan Telkom dengan mudah. Berdasarkan dokumen Terms & Conditions, APILOGY bertujuan untuk memfasilitasi integrasi API dalam aplikasi developer.", "userMessage": "Apa itu APILOGY?", "metadata": { "hasContext": true, "documentsUsed": 3, "topSimilarity": 87, "model": "telkom-ai", "timestamp": "2026-01-27T12:00:00.000Z" }}
Jika response berhasil diterima dengan format yang benar, berarti RAG chatbot Anda telah berfungsi dengan baik.
Troubleshooting
Issue 1: “No text extracted from document”
Gejala: Error saat upload PDF
Penyebab: PDF adalah hasil scan (image-based), bukan text-based
Solusi:
- Pastikan PDF memiliki text layer (bukan hanya gambar)
- Gunakan OCR preprocessing jika diperlukan (Tesseract, Google Vision API)
- Convert ke format text-based menggunakan tools seperti Adobe Acrobat
Issue 2: “No embeddings received from API”
Gejala: Workflow gagal di node Telkom Embedding API
Penyebab:
- API key tidak valid atau kadaluarsa
- Quota API habis
- Network error
Solusi:
- Verifikasi API key di platform APILOGY
- Check quota dan usage limit
- Test API langsung menggunakan curl untuk isolasi masalah
- Implementasi retry logic jika perlu
Issue 3: Similarity scores rendah (< 30%)
Gejala: Bot sering mengatakan informasi tidak tersedia
Penyebab:
- Dokumen yang di-upload tidak relevan dengan pertanyaan
- Chunking size tidak optimal
- Query phrasing kurang tepat
Solusi:
- Upload dokumen yang lebih relevan dengan use case
- Eksperimen dengan chunk size berbeda (300, 700 characters)
- Improve phrasing pertanyaan
- Lower similarity threshold jika perlu (dari 20% ke 15%)
Issue 4: Response time lambat (> 2 detik)
Gejala: Chatbot membutuhkan waktu lama untuk merespons
Penyebab:
- Database terlalu besar (> 10,000 chunks)
- Perhitungan similarity di JavaScript tidak efisien
- Network latency ke API
Solusi:
- Optimize dengan native pgvector query untuk database besar
- Implementasi caching untuk embeddings yang sering diquery
- Pertimbangkan geographic proximity untuk API calls
- Add connection pooling untuk database
Issue 5: LLM response tidak akurat
Gejala: Jawaban tidak sesuai dengan dokumen
Penyebab:
- Context yang diberikan tidak cukup (top 3 chunks tidak mencakup informasi lengkap)
- Prompt engineering kurang optimal
- Temperature terlalu tinggi (terlalu creative)
Solusi:
- Increase jumlah chunks yang di-retrieve (dari 3 ke 5)
- Improve prompt dengan instruksi yang lebih spesifik
- Lower temperature (dari 0.7 ke 0.3)
- Add few-shot examples dalam prompt
Resources
Documentation:
View the full workflow template here
- n8n: https://docs.n8n.io
- Supabase: https://supabase.com/docs
- Telkom LLM: https://www.apilogy.id/api/detail/telkom_ai_dag/name/Telkom-LLM/version/0.0.4
- Telkom Text Embedding: https://www.apilogy.id/api/detail/telkom_ai_dag/name/Text_Embedding/version/0.0.1
- pgvector: https://github.com/pgvector/pgvector
Academic References:
- Lewis et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. NeurIPS.
- Johnson et al. (2019). “Billion-scale similarity search with GPUs”. IEEE Transactions on Big Data.



